Machine Learning in Baseball
The Beginning of Something New
There’s something crazy that is happening right now in baseball, behind the scenes, but very few people understand how it works or even what is going on. One thing is certain though, “baseball nerds” are going to “ruin the game,” if that’s how you want to perceive it.I for one know that is not their intention.
Analytics teams were brought into baseball and many other sports for a reason, and that reason wasn’t to ruin the sport but to improve the team’s performance. How can some nerd that can’t throw a ball straight and has never come close to hitting a fastball over 80mph, which is slightly below average for a Division I NCAA pitcher, possibly help a pitcher strike a batter out or help a team choose which player to add to their roster?
The Athletics started this trend in 2002 when they used On-Base Percentage to select which players they wanted. It is 18 years later though and that methodology is prehistoric. I am not going to waste your time with all of these fancy stats that are being invented to determine player’s areas of strength and weakness because anyone can go to baseball reference or baseball savant and see these statistics. I am going to show you how someone with a Statistics and Actuarial Science degree looks at the beautiful, data rich, game of baseball.
Machine Learning
Machine learning is a scary term if you have no clue what it’s actually referring to; it’s not nearly as complicated as it seems. There are three types of machine learning: Supervised, Unsupervised and Reinforcement. Also I know that definitely complicated your understanding of what you think machine learning is but don’t worry. For now, just think of it as a computer learning from several different records. For example, say you want to know how likely a team is to win. You would feed a bunch of numbers in the form of a data set into a machine and the computer would tell you, based on the past experiences, which team is most likely to win in future games. This example requires one to perform a classification technique, which is a form of supervised learning. The machine does this by using a cost function which differs based on the algorithm you’re using as well as what kind of data you have. At a very basic level the machine creates a line and the cost function is the total difference between that line and all the records in the data set. The way it learns is by trying to minimize the cost function so that the line can be used to predict future points. The line is created from independent variables and is a prediction of the response variable. Generally there is only one response variable but you can have multiple response variables. You would only want to do this under certain conditions though. For example if you were predicting OBP you could also predict Slugging percentage because there is going to be a decently high correlation between the two. 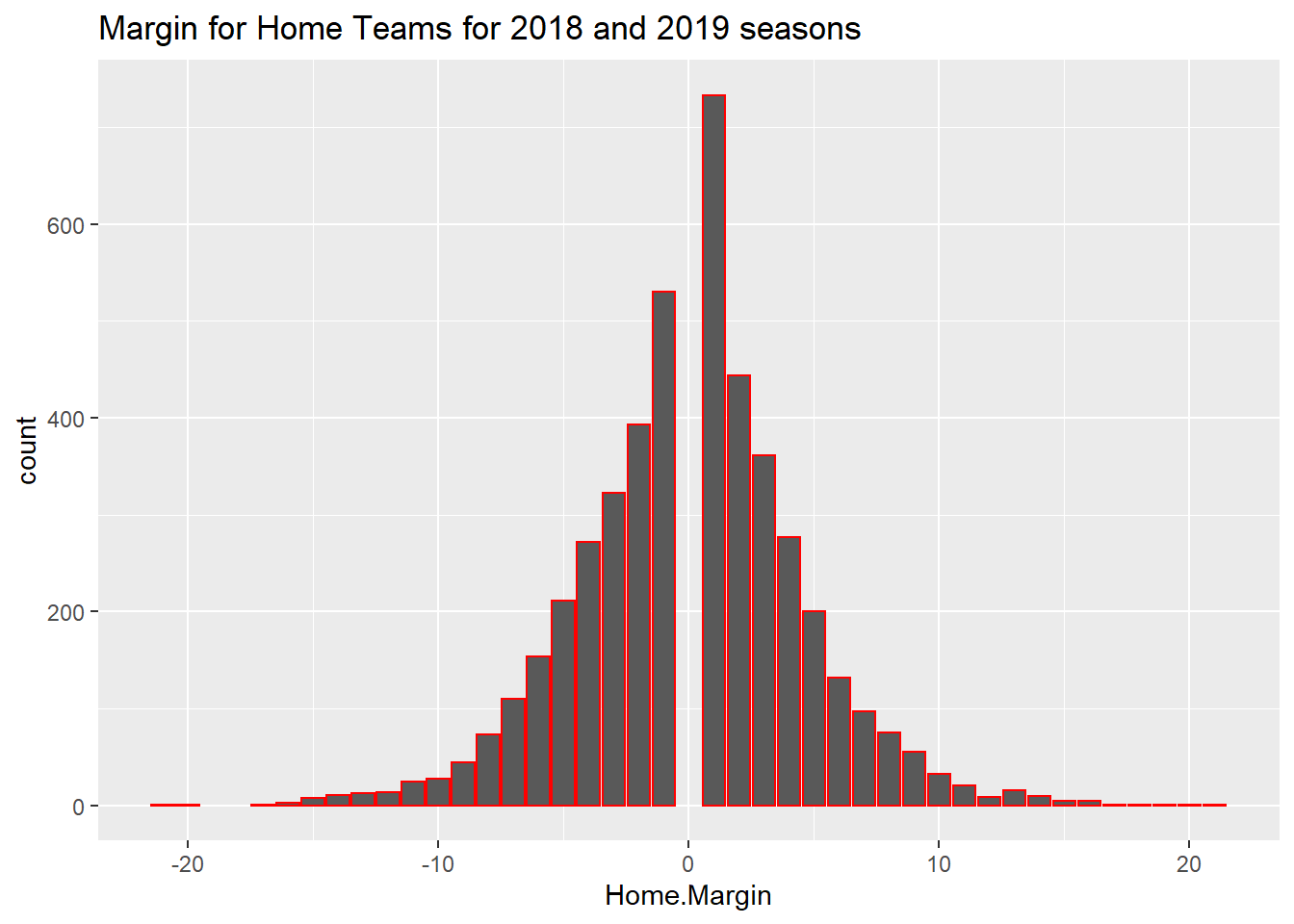
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -21.00000 -3.00000 1.00000 0.06174 3.00000 21.00000## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.0000 0.0000 1.0000 0.5283 1.0000 1.0000Using only the information above, I could make a model that predicts correctly who will win 52.83% of the time and the model would be extremely simple. If the team is home then they will win. This is not a useful model though because each team is different. I will further discuss this in the Classification tab of this website.
Supervised Learning
So why is it call supervised learning? The answer is not someone is always supervising the learning that just doesn’t make sense. Supervised, in this sense, means that a model is being created that outputs a number for each set of independent variables or variables that are used to predict the response variable. There are two forms of supervised learning and I will be discussing both in this website. They are classification and regression. Both of these models can be used in a multivariate sense too which I will dive further into on their respective page.
Unsupervised Learning
Unsupervised learning is another form of machine learning. This process doesn’t give as certain of an answer but it can be useful in certain situations. For example, a right-handed batter might have a tendency to roll over outside pitches to the shortstop. Cluster analysis, a form of unsupervised learning would be able to show you a certain group of pitches and then show you where the batter ended up hitting those pitches. The main idea behind unsupervised learning is to group similar instances together so that more information can be gained for a particular group that is related like grouping all pitchers on whether they throw side-arm, submarine, three-quarters or straight over the top and then seeing if one group tends to get more strikeouts or have more injuries. I will talk more about this on the Clustering Methods page of this website.
Reinforcement Learning
The last type of learning is reinforcement learning and it’s not a form of learning I will be implementing for this website but it can be very useful in baseball. Reinforcement learning is the kind of machine learning that would be responsible for AI taking over the world. The premise behind reinforcement learning is like trying to teach your dog how to sit. You hold the treat out in front of them and only give it to them once they learn the correct action and repeat until you have a strategy that works every time. From there, you build onto the dog’s repertoire by adding a shake or a lay down and reward them for every correct action. Reinforcement learning is letting a computer try to learn the best approach at solving a problem. For every action the computer makes the user gives it a predetermined reward or punishment based on whether the computer made it closer to the end goal or desired solution. From there the computer will forget about the strategies that lead to negative results and continue with ones that lead to rewards until there is a strategy that leads to the right answer every time.
How would an analytics team use this in baseball though. They would use it to either help their team or make it harder for the other team obviously. It would suck if I just left it at that. Teams have used reinforcement learning since the beginning of baseball but they never knew it. Whenever you throw a fastball past a batter and they’re not even close, what pitch is usually the next pitch? Well, why fix something that isn’t broken? You throw fastball after fastball past that batter until he proves that he can hit it. Obviously, the Majors are a little different and you’re not going to give a guy four fastballs in a row unless you’re trying to get taken yard to straight away center but this is the concept of reinforcement learning that was used in baseball’s medieval era.
Pitchers are getting better at making batters miss and if you don’t believe me, go look up how many strikeouts occurred in each season over the last 5 years. The amount of strikeouts has increased every year by a number usually greater than 1,000. This doesn’t seem like much when you consider the fact that around 2,200 games are played each year, but this means that for every two games a team struck out one more time than they did in the previous season and this has happened for several seasons in a row. This trend is only going to get worse because of reinforcement learning. I only realistically have a month of reinforcement learning experience but I could tell you that teams should be using it to build a strategy that gets batters out also known as Pitch Sequencing which I can tell you teams definitely have someone working on. This is something I was doing as a Baseball Data Analytics Intern at Butler University. I wasn’t using Neural Networks or a Markov Decision Process though but rather just looking at how often players missed certain pitches in certain situations. That means looking at where the pitch was, what kind of pitch it was and what the batter ended up doing with it. I would have liked to be able to train a model that gave a strategy on how to strike batters out by setting a reward of 1 for strikes, 0 for balls, and a negative number for contact based on how lethal it was. The model would then learn a strategy to produce the maximum reward (strikeout) for a given batter. I unfortunately would have needed to create a classification model that would have scraped data from pictures giving me information about each pitch that was thrown then used a reinforcement algorithm to create a strategy using the data I scraped and that would have taken way more time than I had. Allowing a machine to create a strategy on how to pitch to batters will make getting hits significantly harder. The opposing team could counter it by doing what the Astros did except in a legal way, with accurate predictions, because machines cannot be random and if they’re making decisions they have a reason for that decision and sometimes it might even be a bad one. There will be a time when the machine’s strategy doesn’t work but the coach or player needs to look at the bigger picture or know when to go against the grain. Imagine a batter is asked to roll a 10-sided dice 100 times and put 1 dollar on it landing on 3 specific number so the batter chooses the numbers 1, 2, and 3. The batter is expected to lose 70 dollars and win 30 dollars, netting them -40 dollars. The pitcher wants the batter to lose as much money as possible. They have no clue which numbers the batter chose but have an idea of which numbers the batter likes and which numbers they hate. If the pitcher can control the dice to land on whichever number they want why would they not set it on numbers that the batter hates? Reinforcement learning makes it easier to find these numbers (pitches) but sometimes the batter will pick a number that he hates and end up getting on base.